Data Preprocessing in Data Mining
Data Integration:
It combines data from multiple sources into a coherent data store, as in data warehousing. These sources may include multiple databases, data cubes, or flat files.
The data integration systems are formally defined as triple<G, S, M>
Where
G: The global schema
S: Heterogeneous source of schemas
M: Mapping between the queries of source and global schema
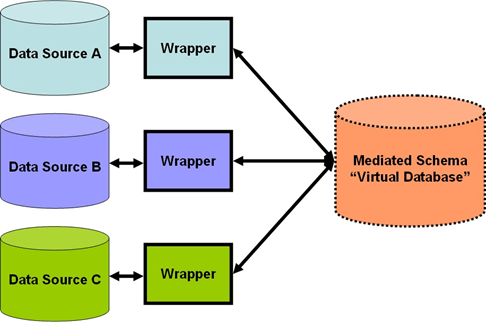
Issues in Data integration:
- Schema integration and object matching:
How can the data analyst or the computer be sure that the customer id in one database and the customer number in another reference to the same attribute?
- Redundancy:
An attribute (such as annual revenue, for instance) may be redundant if it can be derived from another attribute or set of attributes. Inconsistencies in attribute or dimension naming can also cause redundancies in the resulting data set.
- Detection and resolution of data value conflicts:
For the same real-world entity, attribute values from different sources may differ.
Data Transformation:
In data transformation, the data are transformed or consolidated into forms appropriate for mining.
Data transformation can involve the following:
![]() Smoothing, which works to remove noise from the data. Such techniques include binning, regression, and clustering.
Smoothing, which works to remove noise from the data. Such techniques include binning, regression, and clustering.
![]() Aggregation, where summary or aggregation operations are applied to the data. For example, the daily sales data may be aggregated to compute monthly and annual total amounts. This step is typically used in constructing a data cube for analysis of the data at multiple granularities.
Aggregation, where summary or aggregation operations are applied to the data. For example, the daily sales data may be aggregated to compute monthly and annual total amounts. This step is typically used in constructing a data cube for analysis of the data at multiple granularities.
![]() Generalization of the data, where low-level or ―primitive‖ (raw) data are replaced by higher-level concepts through the use of concept hierarchies. For example, categorical attributes, like streets, can be generalized to higher-level concepts, like city or country.
Generalization of the data, where low-level or ―primitive‖ (raw) data are replaced by higher-level concepts through the use of concept hierarchies. For example, categorical attributes, like streets, can be generalized to higher-level concepts, like city or country.
![]() Normalization, where the attribute data are scaled to fall within a small specified range, such as 1:0 to 1:0, or 0:0 to 1:0.
Normalization, where the attribute data are scaled to fall within a small specified range, such as 1:0 to 1:0, or 0:0 to 1:0.
![]() Attribute construction (or feature construction), where new attributes are constructed and added from the given set of attributes to help the mining process.
Attribute construction (or feature construction), where new attributes are constructed and added from the given set of attributes to help the mining process.
Data Reduction:
Data reduction techniques can be applied to obtain a reduced representation of the data set that is much smaller in volume, yet closely maintains the integrity of the original data. That is, mining on the reduced data set should be more efficient yet produce the same (or almost the same) analytical results.
Strategies for data reduction include the following:
![]() Data cube aggregation, where aggregation operations are applied to the data in the construction of a data cube.
Data cube aggregation, where aggregation operations are applied to the data in the construction of a data cube.
![]() Attribute subset selection, where irrelevant, weakly relevant, or redundant attributes or dimensions may be detected and removed.
Attribute subset selection, where irrelevant, weakly relevant, or redundant attributes or dimensions may be detected and removed.
![]() Dimensionality reduction, where encoding mechanisms are used to reduce the dataset size.
Dimensionality reduction, where encoding mechanisms are used to reduce the dataset size.
![]() Numerosity reduction, where the data are replaced or estimated by alternative, smaller data representations such as parametric models (which need to store only the model parameters instead of the actual data) or nonparametric methods such as clustering, sampling, and the use of histograms.
Numerosity reduction, where the data are replaced or estimated by alternative, smaller data representations such as parametric models (which need to store only the model parameters instead of the actual data) or nonparametric methods such as clustering, sampling, and the use of histograms.
![]() Discretization and concept hierarchy generation, where raw data values for attributes are replaced by ranges or higher conceptual levels. Data discretization is a form of numerosity reduction that is very useful for the automatic generation of concept hierarchies. Discretization and concept hierarchy generation are powerful tools for data mining, in that they allow the mining of data at multiple levels of abstraction.
Discretization and concept hierarchy generation, where raw data values for attributes are replaced by ranges or higher conceptual levels. Data discretization is a form of numerosity reduction that is very useful for the automatic generation of concept hierarchies. Discretization and concept hierarchy generation are powerful tools for data mining, in that they allow the mining of data at multiple levels of abstraction.

