To understand, how a search engine works, we can divide the work of search engines into three different stages: crawling, indexing, and retrieval.
Crawling: It is performed by software robots called web spiders or web crawlers. Each search engine has its web spiders to perform crawling. In this step, the spiders visit websites or web pages and read them and follow the links to other web pages of the site. Thus by crawling, they can find out what is published on the World Wide Web. Once the crawler visits a page, it makes a copy of that page and adds its URL to the index.
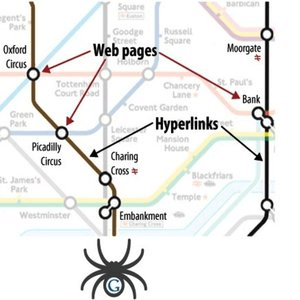
The web spider generally starts crawling with heavily used servers and popular web pages. It follows the route determined by the link structure and finds new interconnected documents through new links. It also revisits the previous sites to check for the changes or updates in the web pages. If changes are found, it makes a copy of the changes to update the index.
Indexing: It involves building an index after crawling all websites or web pages found on the World Wide Web. An index of the crawled sites is made based on the type and quality of information provided by them and stored in huge storage facilities. It is like a book that contains a copy of each webpage crawled by the spider. Thus, it collects and organizes the information from all over the internet.
Retrieval: In this step, the search engine responds to the search queries made by the users by providing a list of websites with relevant answers or information in a particular order. It keeps the relevant websites, which offer unique and original information, on the top of the search engine result pages. So, whenever, a user performs an online search, the search engine searches its database for the websites or web pages with relevant information and make a list of these sites based on their relevancy and present this list to the users on the search engine result pages.


