Web Mining
- Web mining is the art and science of discovering patterns and insights from the World Wide Web so as to improve it.
- The World Wide Web is at the heart of the digital revolution.
- More data is posted on the Web every day than was there on the whole Web just 20 years ago.
- Billions of users are using it every day for a variety of purposes.
- The Web is used for ecommerce, business communication, and many other applications.
- Web mining analyzes data from the Web and helps find insights that could optimize the web content and improve the user experience.
- Data for web mining is collected via web crawlers, web logs, and other means.
Web Mining Structure
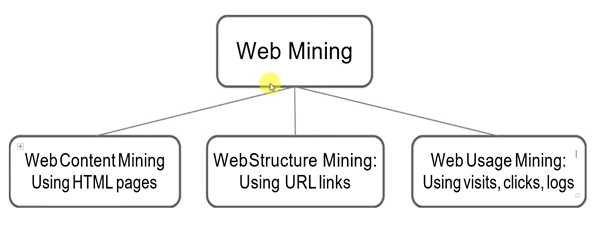
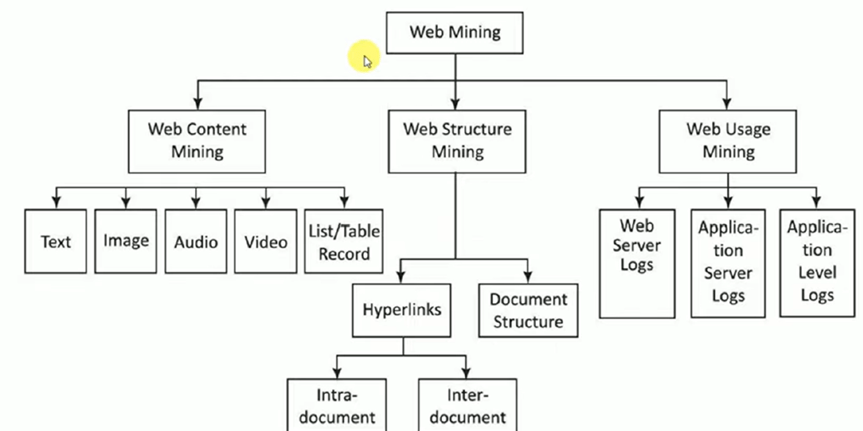
Web Content Mining
- Is the process of extracting useful information from the contents of web documents? Content may consist of text, images, audio, video or structured records, such as lists and tables.
- Web content mining is the application of extracting useful information from the content of the web documents. Web content consist of several types of data — text, image, audio, video etc. Content data is the group of facts that a web page is designed. It can provide effective and interesting patterns about user needs. Text documents are related to text mining, machine learning and natural language processing. This mining is also known as text mining. This type of mining performs scanning and mining of the text, images and groups of web pages according to the content of the input.
Web Content Mining Applications
- Classifying the web documents into categories
- Identifying topics of web documents
- Finding similar web pages across the different web servers
- Applications related to relevance
Web Content Mining Techniques
- Pre-processing of contents
- Clustering
- Classifying
- Identifying the associations
- Topic identification, tracking and drift analysis
Web Structure Mining
- Is the process of discovering structure information from the web? Based on the kind of structure information present in the web resources, web structure mining can be divided into:
- Hyperlinks
- Document Structure
- Web structure mining is the application of discovering structure information from the web. The structure of the web graph consists of web pages as nodes, and hyperlinks as edges connecting related pages. Structure mining basically shows the structured summary of a particular website. It identifies relationship between web pages linked by information or direct link connection. To determine the connection between two commercial websites, Web structure mining can be very useful
Web Usage Mining
- Web usage mining is the application of identifying or discovering interesting usage patterns from large data sets. And these patterns enable you to understand the user behaviors or something like that. In web usage mining, user access data on the web and collect data in form of logs. So, Web usage mining is also called log mining.
Web Usage Mining Applications
- Web Sewer logs: Collected by the web server and typically include IP address, page reference and access time.
- Application Server Logs: Application servers typically maintain their own logging and these logs can be helpful in troubleshooting problems with services
- Application Level Logs: Recording events usually by application software in a certain scope in order to provide an audit trail that can be used to understand the activity of the system and to diagnose problems.
Text mining
- Text mining is the art and science of discovering knowledge, insights, and patterns from an organized collection of textual databases.
- Text is an important part of the growing data in the world.
- Social media technologies have enabled users to become producers of text and images and other kinds of information.
- Text mining can be applied to large-scale social media data for gathering preferences and measuring emotional sentiments.
- It can also be applied to societal, organizational, and individual scales.
Text Mining Process
- Text mining is a semi-automated process.
- Text data needs to be gathered, structured, and then mined, in a three-step process
- The text and documents are first gathered into a corpus and organized.
- The corpus is then analyzed for structure. The result is a matrix mapping important terms to source documents.
- The structured data is then analyzed for word structures, sequences, and frequency.
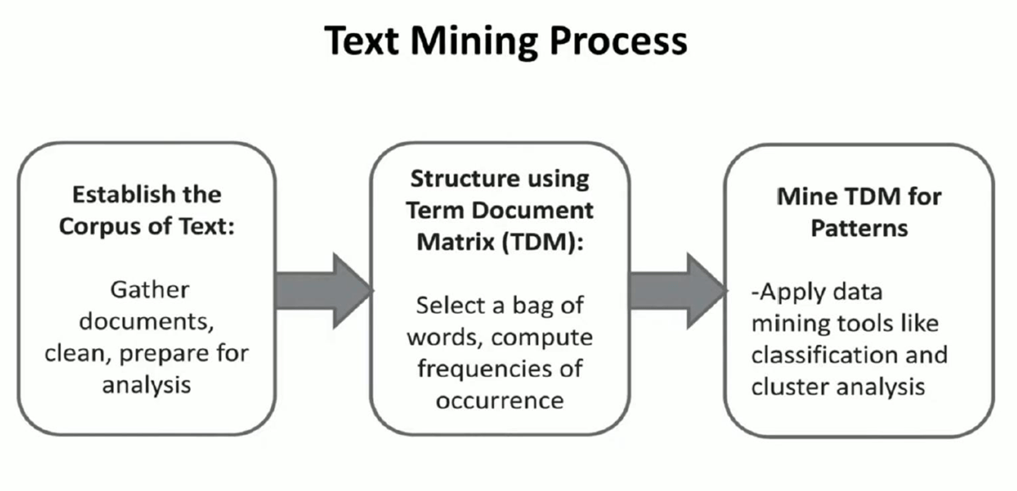
Text Mining Process
- Term-document matrix (TDM): This is the heart of the structuring process. Free flowing text can be transformed into numeric data, which can then be mined using regular data mining techniques.
- The technique used for structuring the text is called the bag-of-words technique. This approach measures the frequencies of select important words and/or phrases occurring in each document. This creates a t x d, term-by-document matrix (TDM), where it is the number of terms and d is the number of documents.
- Creating a TDM requires making choices of which terms to include. The terms chosen should reflect the stated purpose of the text mining exercise. The bag of words should be as extensive as needed, but should not include unnecessary stuP that will serve to confuse the analysis or slow the computation.


